Split
How can we process a message if it contains multiple elements, each of which may have to be processed in a different way?
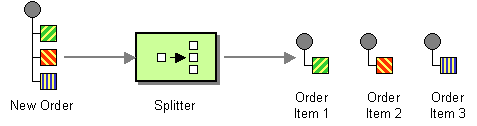
Use a Splitter to break out the composite message into a series of individual messages, each containing data related to one item.
The Splitter from the EIP patterns allows you to split a message into a number of pieces and process them individually.
Options
The Split eip supports 3 options, which are listed below.
| Name | Description | Default | Type |
|---|---|---|---|
note | Sets the note of this node. | String | |
description | Sets the description of this node. | String | |
disabled | Disables this EIP from the route. | false | Boolean |
expression | Required Expression of how to split the message body, such as as-is, using a tokenizer, or using a xpath. | ExpressionDefinition | |
delimiter | Delimiter used in splitting messages. Can be turned off using the value false. To force not splitting then the delimiter can be set to single to use the value as a single list, this can be needed in some special situations. The default value is comma. | , | String |
aggregationStrategy | Sets a reference to the AggregationStrategy to be used to assemble the replies from the split messages, into a single outgoing message from the Splitter. By default Camel will use the original incoming message to the splitter (leave it unchanged). You can also use a POJO as the AggregationStrategy. | AggregationStrategy | |
aggregationStrategyMethodName | This option can be used to explicit declare the method name to use, when using POJOs as the AggregationStrategy. | String | |
aggregationStrategyMethodAllowNull | If this option is false then the aggregate method is not used if there was no data to enrich. If this option is true then null values is used as the oldExchange (when no data to enrich), when using POJOs as the AggregationStrategy. | false | Boolean |
parallelAggregate | Deprecated If enabled then the aggregate method on AggregationStrategy can be called concurrently. Notice that this would require the implementation of AggregationStrategy to be implemented as thread-safe. By default this is false meaning that Camel synchronizes the call to the aggregate method. Though in some use-cases this can be used to archive higher performance when the AggregationStrategy is implemented as thread-safe. | false | Boolean |
parallelProcessing | If enabled then processing each split messages occurs concurrently. Note the caller thread will still wait until all messages has been fully processed, before it continues. It’s only processing the sub messages from the splitter which happens concurrently. When parallel processing is enabled, then the Camel routing engin will continue processing using last used thread from the parallel thread pool. However, if you want to use the original thread that called the splitter, then make sure to enable the synchronous option as well. In parallel processing mode, you may want to also synchronous = true to force this EIP to process the sub-tasks using the upper bounds of the thread-pool. If using synchronous = false then Camel will allow its reactive routing engine to use as many threads as possible, which may be available due to sub-tasks using other thread-pools such as CompletableFuture.runAsync or others. | false | Boolean |
synchronous | Sets whether synchronous processing should be strictly used. When enabled then the same thread is used to continue routing after the split is complete, even if parallel processing is enabled. | false | Boolean |
streaming | When in streaming mode, then the splitter splits the original message on-demand, and each split message is processed one by one. This reduces memory usage as the splitter do not split all the messages first, but then we do not know the total size, and therefore the org.apache.camel.Exchange#SPLIT_SIZE is empty. In non-streaming mode (default) the splitter will split each message first, to know the total size, and then process each message one by one. This requires to keep all the split messages in memory and therefore requires more memory. The total size is provided in the org.apache.camel.Exchange#SPLIT_SIZE header. The streaming mode also affects the aggregation behavior. If enabled then Camel will process replies out-of-order, e.g. in the order they come back. If disabled, Camel will process replies in the same order as the messages was split. | false | Boolean |
stopOnException | Will now stop further processing if an exception or failure occurred during processing of an org.apache.camel.Exchange and the caused exception will be thrown. Will also stop if processing the exchange failed (has a fault message) or an exception was thrown and handled by the error handler (such as using onException). In all situations the splitter will stop further processing. This is the same behavior as in pipeline, which is used by the routing engine. The default behavior is to not stop but continue processing till the end. | false | Boolean |
timeout | Sets a total timeout specified in millis, when using parallel processing. If the Splitter hasn’t been able to send and process all replies within the given timeframe, then the timeout triggers and the Splitter breaks out and continues. The timeout method is invoked before breaking out. If the timeout is reached with running tasks still remaining, certain tasks for which it is difficult for Camel to shut down in a graceful manner may continue to run. So use this option with a bit of care. | 0 | String |
executorService | To use a custom Thread Pool to be used for parallel processing. Notice if you set this option, then parallel processing is automatically implied, and you do not have to enable that option as well. | ExecutorService | |
onPrepare | Uses the Processor when preparing the org.apache.camel.Exchange to be sent. This can be used to deep-clone messages that should be sent, or any custom logic needed before the exchange is sent. | Processor | |
shareUnitOfWork | Shares the org.apache.camel.spi.UnitOfWork with the parent and each of the sub messages. Splitter will by default not share unit of work between the parent exchange and each split exchange. This means each split exchange has its own individual unit of work. | false | Boolean |
outputs | Required | List |
Exchange properties
The Split eip supports 3 exchange properties, which are listed below.
The exchange properties are set on the Exchange by the EIP, unless otherwise specified in the description. This means those properties are available after this EIP has completed processing the Exchange.
| Name | Description | Default | Type |
|---|---|---|---|
CamelSplitIndex | A split counter that increases for each Exchange being split. The counter starts from 0. | int | |
CamelSplitComplete | Whether this Exchange is the last. | boolean | |
CamelSplitSize | The total number of Exchanges that was split. This property is not applied for stream based splitting, except for the very last message because then Camel knows the total size. | int |
Using Split
The following example shows how to take a request from the direct:a endpoint, then split into sub messages, which each are sent to the direct:b endpoint.
The example splits the message body using a tokenizer to split into lines using the new-line character as separator.
from("direct:a")
.split(body().tokenize("\n"))
.to("direct:b");And in XML:
<route>
<from uri="direct:a"/>
<split>
<tokenize token="\n"/>
<to uri="direct:b"/>
</split>
</route>The Split EIP has special support for splitting using a delimiter, instead of using Tokenize language.
The previous example can also be done as follows:
from("direct:a")
.split(body()).delimiter("\n")
.to("direct:b");And in XML:
<route>
<from uri="direct:a"/>
<split delimiter="\n">
<simple>${body}</simple>
<to uri="direct:b"/>
</split>
</route>The splitter can use any Expression, so you could use any of the supported languages such as Simple, XPath, JSonPath, Groovy to perform the split.
-
Java
-
XML
from("activemq:my.queue")
.split(xpath("//foo/bar"))
.to("file:some/directory")<route>
<from uri="activemq:my.queue"/>
<split>
<xpath>//foo/bar</xpath>
<to uri="file:some/directory"/>
</split>
</route>Splitting the message body
A common use case is to split a list/set/collection/map, array, or something that is iterable from the message body.
The Split EIP will by default split the message body based on the value type:
-
java.util.Collection: splits by each element from the collection/list/set. -
java.util.Map: splits by eachMap.Entryfrom the map. -
Object[]: splits the array by each element -
Iterator: splits by the iterator -
Iterable: splits by the iterable -
org.w3c.dom.NodeList: splits the XML document by each element from the list -
String: splits the string value by comma as separator
For any other type, the message body is not split, and instead used as-is, meaning that the Split EIP will be split into a single message (the same).
To use this with the splitter, you should just use body as the expression:
-
Java
-
XML
from("direct:splitUsingBody")
.split(body())
.to("mock:result");In XML, you use Simple to refer to the message body:
<route>
<from uri="direct:splitUsingBody"/>
<split>
<simple>${body}</simple>
<to uri="mock:result"/>
</split>
</route>Splitting with parallel processing
You can enable parallel processing with Split EIP so each split message is processed by its own thread in parallel.
The example below enabled parallel mode:
-
Java
-
XML
from("direct:a")
.split(body()).parallelProcessing()
.to("direct:x")
.to("direct:y")
.to("direct:z");<route>
<from uri="direct:a"/>
<split parallelProcessing="true">
<simple>${body}</simple>
<to uri="direct:b"/>
<to uri="direct:c"/>
<to uri="direct:d"/>
</split>
</route>| When parallel processing is enabled, then the Camel routing engin will continue processing using last used thread from the parallel thread pool. However, if you want to use the original thread that called the splitter, then make sure to enable the synchronous option as well. |
Ending a Split block
You may want to continue routing the exchange after the Split EIP. In Java DSL you need to use end() to mark where split ends, and where other EIPs can be added to continue the route.
In the example above then sending to mock:result happens after the Split EIP has finished. In other words, the message should finish splitting the entire message before the message continues.
-
Java
-
XML
from("direct:a")
.split(body()).parallelProcessing()
.to("direct:x")
.to("direct:y")
.to("direct:z")
.end()
.to("mock:result");And in XML its intuitive as </split> marks the end of the block:
<route>
<from uri="direct:a"/>
<split parallelProcessing="true">
<simple>${body}</simple>
<to uri="direct:b"/>
<to uri="direct:c"/>
<to uri="direct:d"/>
</split>
<to uri="mock:result"/>
</route>What is returned from Split EIP when its complete
The Splitter will by default return the original input message.
You can control this by using a custom AggregationStrategy.
Aggregating
The AggregationStrategy is used for aggregating all the split exchanges together as a single response exchange, that becomes the outgoing exchange after the Split EIP block.
The example now aggregates with the MyAggregationStrategy class:
-
Java
-
XML
from("direct:start")
.split(body(), new MyAggregationStrategy())
.to("direct:x")
.to("direct:y")
.to("direct:z")
.end()
.to("mock:result");And in XML we can refer to the FQN class name with #class: syntax as shown below:
<route>
<from uri="direct:a"/>
<split aggregationStrategy="#class:com.foo.MyAggregationStrategy">
<simple>${body}</simple>
<to uri="direct:b"/>
<to uri="direct:c"/>
<to uri="direct:d"/>
</split>
<to uri="mock:result"/>
</route>| The Multicast, Recipient List, and Splitter EIPs have special support for using |
Splitting modes
The Split EIP operates in two modes when splitting:
-
default mode: The message is split into sub messages, which allows to know the total split size. However, this causes all sub messages to be kept temporary in-memory.
-
streaming mode: The message is split on-demand. This uses an iterator to keep track of the splitting index, but avoids loading all sub messages into memory. However, the total size cannot be known ahead of time.
Using streaming mode
You can split in streaming mode as shown:
-
Java
-
XML
from("direct:streaming")
.split(body().tokenize(",")).streaming()
.to("activemq:my.parts");<route>
<from uri="direct:streaming"/>
<split streaming="true">
<tokenize token=","/>
<to uri="activemq:my.parts"/>
</split>
</route>You can also supply a custom Bean to perform the splitting in streaming mode like this:
-
Java
-
XML
from("direct:streaming")
.split(method(new MyCustomSplitter(), "splitMe")).streaming()
.to("activemq:my.parts")<route>
<from uri="direct:streaming"/>
<split streaming="true">
<method ref="#class:com.foo.MyCustomSplitter" method="splitMe"/>
<to uri="activemq:my.parts"/>
</split>
</route>Then the custom bean could, for example, be implemented as follows:
public class MyCustomSplitter {
public List splitMe(Exchange exchange) {
Object body = exchange.getMessage().getBody();
List answer = new ArrayList();
// split the message body how you like
return answer;
}
}The bean should just return something that the splitter can work with when splitting, such as a List or Iterator etc.
The bean method splitMe uses Exchange as parameter, however, Camel supports Bean Parameter Binding, which allows using other parameters types instead. |
Streaming big XML payloads
| Splitting big XML payloads The XPath engine in Java and Saxon will load the entire XML content into memory. And thus they are not well suited for very big XML payloads. Instead, you can use a custom Expression which will iterate the XML payload in a streamed fashion. You can use the Tokenizer language which supports this when you supply the start and end tokens. You can use the XMLTokenizer language which is specifically provided for tokenizing XML documents. |
There are two tokenizers that can be used to tokenize an XML payload:
-
Tokenize language
-
XML Tokenize language
Streaming big XML payloads using Tokenize language
The first tokenizer uses the same principle as in the text tokenizer to scan the XML payload and extract a sequence of tokens. If you have a big XML payload, from a file source, and want to split it in streaming mode, then you can use the Tokenize language with start/end tokens to do this with low memory footprint.
| StAX component The Camel StAX component can also be used to split big XML files in a streaming mode. See more details at StAX. |
For example, you may have an XML payload structured as follows:
<orders>
<order>
<!-- order stuff here -->
</order>
<order>
<!-- order stuff here -->
</order>
...
<order>
<!-- order stuff here -->
</order>
</orders>Now to split this big file using XPath would cause the entire content to be loaded into memory. So instead, we can use the Tokenize language to do this as follows:
-
Java
-
XML
from("file:inbox")
.split().tokenizeXML("order").streaming()
.to("activemq:queue:order");<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order" xml="true"/>
<to uri="activemq:queue:order"/>
</split>
</route>This will split the file using the tag name of the child nodes (more precisely speaking, the local name of the element without its namespace prefix if any), which mean it will grab the content between the <order> and </order> tags (incl. the tags).
So for example, a split message would be structured as follows:
<order>
<!-- order stuff here -->
</order>If you want to inherit namespaces from a root/parent tag, then you can do this as well by providing the name of the root/parent tag:
-
Java
-
XML
from("file:inbox")
.split().tokenizeXML("order", "orders").streaming()
.to("activemq:queue:order");<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="order" inheritNamespaceTagName="orders" xml="true"/>
<to uri="activemq:queue:order"/>
</split>
</route>You can set inheritNamsepaceTagName property to * to include the preceding context in each token (i.e., generating each token enclosed in its ancestor elements). It is noted that each token must share the same ancestor elements in this case. The above tokenizer works well on simple structures but has some inherent limitations in handling more complex XML structures.
Streaming big XML payloads using XML Tokenize language
The second tokenizer (XML Tokenize) uses a StAX parser to overcome these limitations. This tokenizer recognizes XML namespaces and also handles simple and complex XML structures more naturally and efficiently.
To split with XML namespaces on a tag with a local namespace such as {urn:shop}order, we can write:
Namespaces ns = new Namespaces("ns1", "urn:shop");
from("file:inbox")
.split().xtokenize("//ns1:order", 'i', ns).streaming()
.to("activemq:queue:order)Two arguments control the behavior of the tokenizer:
-
The first argument specifies the element using a path notation This path notation uses a subset of xpath with wildcard support.
-
The second argument represents the extraction mode.
The available extraction modes are:
| Mode | Description |
|---|---|
i | injecting the contextual namespace bindings into the extracted token (default) |
w | wrapping the extracted token in its ancestor context |
u | unwrapping the extracted token to its child content |
t | extracting the text content of the specified element |
Having an input XML:
<m:orders xmlns:m="urn:shop" xmlns:cat="urn:shop:catalog">
<m:order><id>123</id><date>2014-02-25</date>...</m:order>
...
</m:orders>Each mode will result in the following tokens:
| Mode | Description |
|---|---|
i | <m:order xmlns:m="urn:shop" xmlns:cat="urn:shop:catalog"><id>123</id><date>2014-02-25</date>…</m:order> |
w | <m:orders xmlns:m="urn:shop" xmlns:cat="urn:shop:catalog"> <m:order><id>123</id><date>2014-02-25</date>…</m:order> </m:orders> |
u | <id>123</id><date>2014-02-25</date>… |
t | 1232014-02-25… |
In XML, the equivalent route would be written as follows:
<camelContext xmlns:ns1="urn:shop">
<route>
<from uri="file:inbox"/>
<split streaming="true">
<xtokenize>//ns1:order</xtokenize>
<to uri="activemq:queue:order"/>
</split>
</route>
</camelContext>or setting the extraction mode explicitly as
<xtokenize mode="i">//ns1:order</xtokenize>Note that this StAX based tokenizer uses StAX Location API and requires a StAX Reader implementation (such as Woodstox) that correctly returns the offset position pointing to the beginning of each event triggering segment (the offset position of < at each start and end element event). If you use a StAX Reader which does not implement that API correctly, it results in invalid XML snippets after the split.
For example, the snippet could be wrongly terminated:
<Start>...<</Start> .... <Start>...</</Start>Splitting files by grouping N lines together
The Tokenize language can be used for grouping N parts together, for example, to split big files into chunks of 1000 lines.
Doing this is easy as the following example shows:
-
Java
-
XML
from("file:inbox")
.split().tokenize("\n", 1000).streaming()
.to("activemq:queue:order");<route>
<from uri="file:inbox"/>
<split streaming="true">
<tokenize token="\n" group="1000"/>
<to uri="activemq:queue:order"/>
</split>
</route>The group value must be a positive number dictating how many elements to combine in a group. Each part will be combined using the token.
In the example above, the message being sent to the activemq order queue, will contain 1000 lines, and each line separated by the token (which is a new line token).
The output when using the group option is always a java.lang.String type.
Split and aggregate example
This sample shows how you can split an Exchange, process each split message, aggregate and return a combined response to the original caller.
The route below illustrates this and how the split supports a custom AggregationStrategy to build up the combined response message.
// this routes starts from the direct:start endpoint
// the body is then split based on @ separator
// the splitter in Camel supports InOut as well, and for that we need
// to be able to aggregate what response we need to send back, so we provide our
// own strategy with the class MyOrderStrategy.
from("direct:start")
.split(body().tokenize("@"), new MyOrderStrategy())
// each split message is then send to this bean where we can process it
.to("bean:MyOrderService?method=handleOrder")
// this is important to end the splitter route as we do not want to do more routing
// on each split message
.end()
// after we have split and handled each message, we want to send a single combined
// response back to the original caller, so we let this bean build it for us,
// this bean will receive the result of the aggregate strategy: MyOrderStrategy
.to("bean:MyOrderService?method=buildCombinedResponse")And the OrderService bean is as follows:
public static class MyOrderService {
private static int counter;
/**
* We just handle the order by returning an id line for the order
*/
public String handleOrder(String line) {
LOG.debug("HandleOrder: {}", line);
return "(id=" + ++counter + ",item=" + line + ")";
}
/**
* We use the same bean for building the combined response to send
* back to the original caller
*/
public String buildCombinedResponse(String line) {
LOG.debug("BuildCombinedResponse: {}", line);
return "Response[" + line + "]";
}
}And our custom AggregationStrategy that is responsible for holding the in progress aggregated message that after the splitter is ended will be sent to the buildCombinedResponse method for final processing before the combined response can be returned to the waiting caller.
/**
* This is our own order aggregation strategy where we can control
* how each split message should be combined. As we do not want to
* loos any message we copy from the new to the old to preserve the
* order lines as we process them
*/
public static class MyOrderStrategy implements AggregationStrategy {
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
// put order together in old exchange by adding the order from new exchange
if (oldExchange == null) {
// the first time we aggregate we only have the new exchange,
// so we just return it
return newExchange;
}
String orders = oldExchange.getIn().getBody(String.class);
String newLine = newExchange.getIn().getBody(String.class);
LOG.debug("Aggregate old orders: {}", orders);
LOG.debug("Aggregate new order: {}", newLine);
// put orders together separating by semicolon
orders = orders + ";" + newLine;
// put combined order back on old to preserve it
oldExchange.getIn().setBody(orders);
// return old as this is the one that has all the orders gathered until now
return oldExchange;
}
}So let’s run the sample and see how it works.
We send an Exchange to the direct:start endpoint containing a message body with the String value: A@B@C. The flow is:
HandleOrder: A
HandleOrder: B
Aggregate old orders: (id=1,item=A)
Aggregate new order: (id=2,item=B)
HandleOrder: C
Aggregate old orders: (id=1,item=A);(id=2,item=B)
Aggregate new order: (id=3,item=C)
BuildCombinedResponse: (id=1,item=A);(id=2,item=B);(id=3,item=C)
Response to caller: Response[(id=1,item=A);(id=2,item=B);(id=3,item=C)]Stop processing in case of exception
The Splitter will by default continue to process the entire Exchange even in case of one of the split messages will throw an exception during routing.
For example, if you have an Exchange with 1000 rows that you split. During processing of these split messages, an exception is thrown at the 17th. What Camel does by default is to process the remainder of the 983 messages. You have the chance to deal with the exception when aggregating using an AggregationStrategy.
But sometimes you want Apache Camel to stop and let the exception be propagated back, and let the Camel Error Handler handle it. You can do this by specifying that it should stop in case of an exception occurred. This is done by the stopOnException option as shown below:
-
Java
-
XML
from("direct:start")
.split(body().tokenize(",")).stopOnException()
.process(new MyProcessor())
.to("mock:split")
.end()
.to("direct:cheese");<route>
<from uri="direct:start"/>
<split stopOnException="true">
<tokenize token=","/>
<process ref="myProcessor"/>
<to uri="mock:split"/>
</split>
<to uri="direct:cheese"/>
</route>In the example above, then MyProcessor is causing a failure and throws an exception. This means the Split EIP will stop after this, and not split anymore.
Sharing unit of work
The Splitter will by default not share unit of work between the parent exchange and each split exchange. This means each sub exchange has its own individual unit of work.
For example, you need to split a big message, and regard that process as an atomic-isolated operation that either is a success or failure. In case of a failure, you want that big message to be moved into a dead letter queue.
To support this use case, you would have to share the unit of work on the Splitter.
Here is an example in Java DSL:
errorHandler(deadLetterChannel("mock:dead").useOriginalMessage()
.maximumRedeliveries(3).redeliveryDelay(0));
from("direct:start")
.to("mock:a")
// share unit of work in the splitter, which tells Camel to propagate failures from
// processing the split messages back to the result of the splitter, which allows
// it to act as a combined unit of work
.split(body().tokenize(",")).shareUnitOfWork()
.to("mock:b")
.to("direct:line")
.end()
.to("mock:result");
from("direct:line")
.to("log:line")
.process(new MyProcessor())
.to("mock:line");What would happen is that in case there is an exception thrown during splitting, then the error handler will kick in (yes error handling still applies for the sub messages).
The error handler in this example is configured to retry up till three times. And when a split message fails all redelivery attempts (its exhausted), then this message is not moved into that dead letter queue.
The reason is that we have shared the unit of work, so the split message will report the error on the shared unit of work. When the Splitter is done, it checks the state of the shared unit of work and checks if any errors occurred. If an error occurred it will set the exception on the Exchange and mark it for rollback.
The error handler will yet again kick in, as the Exchange has been marked as rollback. No redelivery attempts are performed (as it was marked for rollback) and the Exchange will be moved into the dead letter queue.
Using this from XML DSL is just as easy as all you have to set is the shareUnitOfWork:
<camelContext errorHandlerRef="dlc" xmlns="http://camel.apache.org/schema/spring">
<!-- define error handler as DLC, with use original message enabled -->
<errorHandler id="dlc" type="DeadLetterChannel" deadLetterUri="mock:dead" useOriginalMessage="true">
<redeliveryPolicy maximumRedeliveries="3" redeliveryDelay="0"/>
</errorHandler>
<route>
<from uri="direct:start"/>
<to uri="mock:a"/>
<!-- share unit of work in the splitter, which tells Camel to propagate failures from
processing the split messages back to the result of the splitter, which allows
it to act as a combined unit of work -->
<split shareUnitOfWork="true">
<tokenize token=","/>
<to uri="mock:b"/>
<to uri="direct:line"/>
</split>
<to uri="mock:result"/>
</route>
<!-- route for processing each split line -->
<route>
<from uri="direct:line"/>
<to uri="log:line"/>
<process ref="myProcessor"/>
<to uri="mock:line"/>
</route>
</camelContext>See Also
Because Multicast EIP is a baseline for the Recipient List and Split EIPs, then you can find more information in those EIPs about features that are also available with Split EIP.